published: January 8, 2011 — tags: django, postgresql, sql
Nested SQL for calculations inside database.
Ever needed to recalculate some fields in your Django models and wondered how it can be done efficiently? SQL might be the answer. Let me first explain the problem that made me think about it.
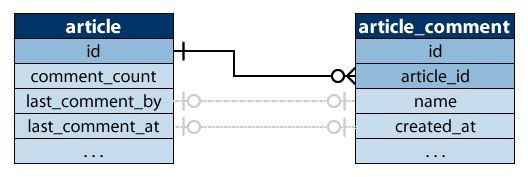
I use two models dealing with articles: Article and ArticleComment. The relationship between them is displayed in the ERM diagram below. There's just one foreign key relationship linking each comment to an article. The grey lines show denormalised relationships that aren't managed by the database but the application. Perhaps using foreign keys would give some benefits - i.e. when a comment is deleted, the fields in the corresponding article are marked as NULL by cascading. I am however not going to delete comments, only set their visible field to false.
Whenever a new comment is added, the Article object is updated with data from the comment (last_comment_by, and last_comment_at) and comment_count is incremented. All is fine, but what to do when a comment is made invisible? We could check whether last_comment_at equals comment's created_at and then re-evaluate the fields in article. It seems logical, article fields are always up-to-date when using this method.
But sometimes you make an error in the application, edit comments' visibility using a different tool (such as database command line client) or just don't care about adding this extra logic to your application and the few minutes during which last_comment_by points nowhere don't bother you. In all those cases you end up with inconsistent data.
There should be a way to correct all these inconsistencies on demand. I have an extra button on the interface to recalculate comment data, just in case it's wrong. There's only one requirement for this operation besides accuracy - it has to be fast.
How to update all article data at once?
There are several ideas. The first natural choice is to try doing it with Django's ORM. You will probably end up with code like this:
Article.objects.update(last_comment_by='', last_comment_at=None, comment_count=0) comments = ArticleComment.objects.filter(visible=True).only( 'article', 'name', 'created_at').order_by('article', 'created_at') last = {} counter = {} for c in comments: aid = c.article_id last[aid] = [c.created_at, c.name] counter[aid] = counter[aid] + 1 if counter.has_key(aid) else 1 for aid in last: Article.objects.filter(id=aid).update(comment_count=counter[aid], last_comment_at=last[aid][0], last_comment_by=last[aid][1])
Actually it looks quite nice (from python's perspective). The added defer makes sure that we don't load fields we don't need, especially the comment body, which can be quite big. This is a pretty straightforward solution to use for a small site, with a limited number of articles. For bigger sites you would want to look at the cost of this operation.
Let's see what SQL statements are performed in the background:
UPDATE "article" SET "comment_count" = 0, "last_comment_by" = E'', "last_comment_at" = NULL; SELECT "article_comment"."id", "article_comment"."article_id", "article_comment"."name", "article_comment"."created_at" FROM "article_comment" WHERE "article_comment"."visible" = true ORDER BY "article_comment"."article_id" ASC, "article_comment"."created_at" ASC; UPDATE "article" SET "comment_count" = 37, "last_comment_at" = E'2011-01-05 09:04:02.950000', "last_comment_by" = E'Anonymous' WHERE "article"."id" = 1; -- last statement repeated 3 times because 4 articles had comments
Data is moved into python, converted to python objects, then converted back and saved in article rows one article at a time! When I tested it on my Windows-infected development machine, with only 4 articles having any comments and 45 comments in total, it took about 160 milliseconds to run. Imagine now a site with tens of thousands of comments.
At that point it is better to let the database handle this task without moving the data around and processing it in an external application. It was tested with Postgresql. Other database may have a different and perhaps simpler way of using nested SQL statements.
How to let the database server do the work?
This time the same task will be performed using SQL. This is Postgresql's query:
UPDATE article SET comment_count = 0, last_comment_by = '', last_comment_at = NULL; UPDATE article SET comment_count = foo.cc FROM ( SELECT article_id as aid, count(*) as cc FROM article_comment WHERE visible = true GROUP BY article_id ) as foo WHERE article.id = aid; UPDATE article SET last_comment_by = foo.name, last_comment_at = foo.created_at FROM ( SELECT DISTINCT ON (article_id) article_id as aid, created_at, name FROM article_comment WHERE visible = true ORDER BY article_id ASC, created_at DESC ) as foo WHERE article.id = aid;
and this is the python code to be used:
query = """ (put those queries here) """ from django.db import connection c = connection.cursor() c.execute(query) c.execute("COMMIT") c.execute("BEGIN") c.close()
COMMIT and BEGIN are only required when Django is running with open transactions (which is the default as far as I know). This time it only took on average 26 milliseconds. When to use this solution instead of the pure Django one?
- when you have lots of records to update and can't do it in one call
- when there would otherwise be to big amount of data moved around
- when the database server is efficient and has functions doing things better
- when you don't know Django's ORM as well as you know SQL
I wonder how this query would look in MySQL...
Add your comment